
論文というものはすぐにたまる.読みもしないのにどんどんたまる.21世紀に入った頃は論文のプリントアウトの山ができて定期的に捨てたりしていたのだが,それも今は昔,現在はpdfの時代であり,かなり前からpdfで読んで,注釈など書き込んだりするようになった.しかし,どんどんたまるのは昔以上である.何しろ取るスペースはディスクの容量だけで,物理空間を占拠するわけではないから,いくらでも気兼ねなくため込める.ため込んだ論文数が数千を越えるあたりで,ふと思うわけである.「これを全て読むのは不可能としても,全文検索ができたら便利だろうなぁ...」
という訳で,今回は,hyperestraierを使ってため込んだpdfの全文検索をできるようにしようという話である.
hyperestraierをインストールし,Apacheをセットアップして,pdf文書のインデックスを作成し,これをブラウザで検索できるようにするという流れでまとめていく.
セットアップは結構面倒だが,非常に便利で,オススメである!
なお,以下の手順は,MacBook Pro (15-inch, Late 2016) Mojave 10.14.6,および,iMac 2012 Mojave 10.14.6 の両方で確認済みである.
References
- Hyper Estraier で仏典探索 Amrtaさんのものすごく役に立つサイト
- Hyper Estraier で PDF 管理 これまた,Amrtaさんの物凄く役に立つサイト.以上の2つを読めば,このサイトを見る必要はないような...(^^;;;
sudoしてrootになるのはイヤ,普通のユーザーとしてapacheを使ってブラウザで全文検索をしたいという人は,この先を読むと参考になるかもしれない.
Hyper Estraier
今回用いるのはHyper Estraierという全文検索システムである.これがどんなものかはリンク先の文書を読んでもらうとして,早速インストールである.
Install
homebrewを使用すれば一発である.qdbmなどの依存関係も全部面倒を見てくれるので楽である.
$ brew install hyperestraier
インストールされたものを見るとこうなっている.
$ brew info hyperestraier
hyperestraier: stable 1.4.13 (bottled)
Full-text search system for communities
https://fallabs.com/hyperestraier/
/usr/local/Cellar/hyperestraier/1.4.13 (278 files, 3.1MB) *
Built from source on 2016-12-24 at 22:34:54 with: --with-mecab
From: https://github.com/Homebrew/homebrew-core/blob/master/Formula/hyperestraier.rb
==> Dependencies
Required: qdbm
==> Analytics
install: 3 (30 days), 16 (90 days), 64 (365 days)
install_on_request: 3 (30 days), 16 (90 days), 64 (365 days)
build_error: 0 (30 days)
pdfのindexを作成する際に,hyperestraierに含まれているestfxpdftohtmlというフィルタでPDFのファイルをHTML形式に変換する.しかし,このフィルタは/usr/local/bin/などには入ってくれないので,brewによりインストールされた場所を探して,pathの通るところにsymbolic linkを張っておく.
$ mdfind -name filter | grep hyperestraier
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/filter
$ ls -al /usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/filter
total 48
drwxr-xr-x 8 kohkichi admin 256 Feb 16 2017 ./
drwxr-xr-x 19 kohkichi admin 608 Dec 24 2016 ../
-rwxr-xr-x 1 kohkichi admin 1118 Dec 24 2016 estfxasis*
-rwxr-xr-x 1 kohkichi admin 1063 Dec 24 2016 estfxmantotxt*
-rwxr-xr-x 1 kohkichi admin 1263 Dec 24 2016 estfxmsotohtml*
-rwxr-xr-x 1 kohkichi admin 1016 Dec 24 2016 estfxpdftohtml*
-rwxr-xr-x 1 kohkichi admin 1007 Dec 24 2016 estfxxdwtotxt*
-rwxr-xr-x 1 kohkichi admin 1057 Dec 24 2016 estwnetxpnd*
$ ln -s /usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/filter/* /usr/local/bin/
pdftotext
上述のestfxpdftohtmlであるが,内部でpdftotextを使用している.そして,厄介なことに,このpdftotextはxpdfとpopplerの両方に含まれている.しかも,xpdfに含まれているpdftotextには -htmlmeta optionがないのである.つまり, xpdfに含まれているpdftotextを使用するとpdf文書のindexができない ということになる.実際にそれぞれのversionを見てみると,
<<xpdf>>
$ pdftotext -h
pdftotext version 4.01.01
Copyright 1996-2019 Glyph & Cog, LLC
..........
<<poppler>>
$ pdftotext -h
pdftotext version 0.77.0
Copyright 2005-2019 The Poppler Developers - http://poppler.freedesktop.org
Copyright 1996-2011 Glyph & Cog, LLC
..........
このように,全く異なったものになっているが,どうやら,xpdfのものの方が古いらしい.もし,xpdfをすでに入れている場合は,popplerをインストールしようとすると,
$ brew install poppler
Error: Cannot install poppler because conflicting formulae are installed.
xpdf: because poppler, pdftohtml, pdf2image, and xpdf install conflicting executables
Please `brew unlink xpdf` before continuing.
と怒られるので,言われる通りに brew unlink xpdf してから,再度,brew install popplerを行えば良い.これで,popplerの方のpdftotextが使われるようになって,ちゃんとindexができるようになる.私は2台あるMacの片方でだけ何故かindexが作成できないので,原因を調べているうちにこのことに気がついたが,ネットで他に触れている記事が見当たらないので,ここにまとめておく.
また,このようにしてxpdfとpopplerをインストールしていると, Emacsでpdfを読む (pdf-tools) (2019.07.17追記)に書いたように,pdf-toolをコンパイルする際に「libffiがどこにあるか分からん」というようなエラーメッセージが出ることがある.その際の対処法は, Emacsでpdfを読む (pdf-tools) (2019.07.17追記)に書いたとおりである.
ユーザー用のウェブディレクトリの作成
まず,Apacheを用いてブラウザで検索できるように(これについては後述),自分のhome directoryにSitesというdirectoryを作成する.
$ cd ~
$ mkdir Sites
$ cd Sites
$ pwd
/Users/taipapa/Sites
Apacheの設定のところで述べるが,このSitesというディレクトリにウェブサイトを構築できるように設定し,WWW ブラウザで全文検索できるようにする.
全文検索用のディレクトリの作成
Sites ディレクトリの中に全文検索用のディレクトリを作成する.ここではpdfファイルの全文検索を行うので,pdfという名前にした.さらに,pdf ディレクトリの中に全文検索の対象となるpdfを集約するためのPDFsというディレクトリを作成する.
$ cd ~/Sites
$ mkdir pdf
$ cd pdf
$ mkdir PDFs
PDFsディレクトリへのpdfの集約
さて,pdfは,大抵の場合,いくつかのディレクトリに分けて置いてあるであろう.それを全て1箇所に集約して全文検索ができるようにするために,シンボリックリンクを使用する.具体的には,pdfのあるディレクトリが,/Data/hogehoge, /Data/fugaguga, /Data/misc とすると,以下のようにする.
$ cd /Users/taipapa/Sites/pdf/PDFs
$ ln -s /Data/hogehoge .
$ ln -s /Data/fugafuga .
$ ln -s /Data/misc .
全文検索用のindexの作成
hyperestraierのestcmdを用いて,空のindexを作成する.名前はマニュアルの真似をしてcasketとする(わかれば何でも良いと思う).これはpdfの配下でPDFsと同じレベルに置く
$ pwd
/Users/taipapa/Sites/pdf
$ estcmd create casket
$ ls -la
total 24
drwxr-xr-x 5 taipapa staff 160 Jul 29 20:34 .
drwxr-xr-x 8 taipapa staff 256 Aug 4 22:19 ..
-rw-r--r--@ 1 taipapa staff 8196 Aug 5 22:12 .DS_Store
drwxr-xr-x 10 taipapa staff 320 Jul 29 20:21 PDFs
drwxr-xr-x 11 taipapa staff 352 Jul 29 21:14 casket
これでようやく,indexを作成する準備が整った.後は以下のように叩けば良い.optionについてはマニュアルを参照.
$ cd /Users/taipapa/Sites/pdf
$ estcmd gather -pc UTF-8 -cl -fx ".pdf" "H@estfxpdftohtml" -il ja -lf -1 -sd -cm -um casket PDFs
document数が11734個,語数が1351563のindex作成に要した時間は約40分強であった.これは,MacBook Pro (15-inch, Late 2016)でもiMac 2012 でも,ほとんど変わらなかった.
optionとしては,optimizeがインデックスを最適化して、不要な領域を削除,purgeはインデックス内にあってファイルシステム上にない文書の情報を削除する.
$ cd /Users/taipapa/Sites/pdf
$ estcmd optimize /Library/WebServer/Documents/pdf/casket
$ estcmd purge -cl /Library/WebServer/Documents/pdf/casket
$ cd /Users/taipapa/Sites/pdf
$ estcmd optimize /Users/taipapa/Sites/pdf/casket
$ estcmd purge -cl /Users/taipapa/Sites/pdf/casket
indexの更新
前述の3つのコマンドを打てば良い.
$ cd /Users/taipapa/Sites/pdf
$ estcmd gather -pc UTF-8 -cl -fx ".pdf" "H@estfxpdftohtml" -il ja -lf -1 -sd -cm -um casket PDFs
$ estcmd optimize /Library/WebServer/Documents/pdf/casket
$ estcmd purge -cl /Library/WebServer/Documents/pdf/casket
$ cd /Users/taipapa/Sites/pdf
$ estcmd gather -pc UTF-8 -cl -fx ".pdf" "H@estfxpdftohtml" -il ja -lf -1 -sd -cm -um casket PDFs
$ estcmd optimize /Users/taipapa/Sites/pdf/casket
$ estcmd purge -cl /Users/taipapa/Sites/pdf/casket
最初にゼロからindexを作成する際は,上記のようにかなり時間がかかるが,一旦作ってしまえば,更新はごく短時間で終了する.更新の自動化については,Amrtaさんの インデックス更新の自動化 を参考にされたい.
検索のテスト
試しにterminalで検索してみる.
$ cd /Users/taipapa/Sites/pdf
$ estcmd search -vh casket HSP27
--------[02D18ACF711B9586]--------
VERSION 1.0
NODE local
HIT 288
HINT#1 hsp27 288
TIME 0.001226
DOCNUM 11734
WORDNUM 1354563
VIEW HUMAN
..........
うん,ちゃんと動いている.それに速い!
Apache set up
terminalで検索ではあまりに寂しいので,ブラウザで検索できるようにするために,Web serverを立ち上げる.MacにはデフォルトでApacheがインストールされているというありがたい状態になっているので,これを使う.なお,Apacheについては,Apacheとは?Webサーバーの仕組みと人気サーバーソフトを徹底解説などを参考にされたい.
Apacheの設定については,以下を参考にした.
- 参考1:Macでローカルサーバを立ち上げる方法
- 参考2:MacでApacheを立ち上げてみる
- 参考3:Macでローカルサーバー構築あれこれ
- 参考4:Apache Tutorial: CGI による動的コンテンツ (結局,きちんと理解する為には,これをはじめとするApacheのチュートリアルを読むのが一番であった)
これらのサイトを読んだ方が早いのだが,自分のために設定などをまとめておく.
まず,念のためにApacheが既にインストールされているかどうかを確かめてみる.
$ httpd -v
Server version: Apache/2.4.34 (Unix)
Server built: Feb 22 2019 20:20:11
確かにインストールされている.
CGI を許可するように Apache を設定する
-
Apacheの設定ファイルの場所は、/etc/apache2/httpd.conf
-
CGI (Common Gateway Interface) は,ウェブサーバが コンテンツ生成をする外部プログラムと協調して動作するための方法を 定義している.
-
CGI プログラムを正しく動作させるには、CGI を許可するように Apache の設定を行う必要がある.
-
Apache が共有モジュール機能付きでビルドされている場合、モジュールがロードされていることを確認する.具体的には,/etc/apache2/httpd.conf をviを使って以下のように書き換えれば良い(root権限が必要なので sudo している).
sudo vi /etc/apache2/httpd.conf .... 165 #LoadModule cgi_module libexec/apache2/mod_cgi.so -----> LoadModule cgi_module libexec/apache2/mod_cgi.so165行目の行頭の#を外してアンコメントし,有効化しておく.
これをやらないと,cgiが働かず,そのファイル自体がダウンロードされてしまう. -
設定ファイルの更新内容を反映させるためにはApacheの再起動が必要
Apacheの起動,再起動
-
Apacheの起動
$ sudo apachectl start- Apacheの停止
$ sudo apachectl stop- Apacheの再起動
$ sudo apachectl restart
これでApacheを起動したので,hyperestraierに含まれている検索用CGI scriptを利用する.
CGIが動くかどうかのテスト
Apache Tutorial: CGI による動的コンテンツ には,「ScriptAlias ディレクティブを使用して、 CGI プログラム用の特別な別ディレクトリを Apache に設定します。 Apache は、このディレクトリ中の全てのファイルを CGI プログラムであると仮定します。 そして、この特別なリソースがクライアントから要求されると、 そのプログラムの実行を試みます。」と記載されている.一方, mojaveのデフォルトの /etc/apache2/httpd.confでは,ScriptAliasではなく,以下のようにScriptAliasMatchを用いている.
373 ScriptAliasMatch ^/cgi-bin/((?!(?i:webobjects)).*$) "/Library/WebServer/CGI-Executables/$1"
この正規表現の記述により,cgi-bin/というパスが/Library/WebServer/CGI-Executables/に対応するようになっている(詳細は,ScriptAlias ディレクティブ のScriptAliasMatch ディレクティブを参照)
ということで,/Library/WebServer/CGI-Executables/にcgi scriptを置けば,CGI programとして動くはずである.macでは最初からperlがインストールされているので,以下のようなperl script(“Hello"と表示するだけ)を作成して試してみる.
#!/usr/bin/perl
print "Content-type: text/html \n\n";
print "Hello";
これを,test.cgiとして保存し,
$ chomod 755 test.cgi
して,実行権限を付与した上で,/Library/WebServer/CGI-Executables/に置く.この状態で,ブラウザのurl windowに localhost/cgi-bin/test.cgi と打ち込むと,“Hello” と表示される.
さて,次の段階に進む前にDocumentRootについて,ちょっと説明が必要(後日の自分のため).
DocumentRoot
/etc/apache2/httpd.confを,lessを使って読んでみると以下のように書かれている.
$ less -N /etc/apache2/httpd.conf
..........
240 #
241 # DocumentRoot: The directory out of which you will serve your
242 # documents. By default, all requests are taken from this directory, but
243 # symbolic links and aliases may be used to point to other locations.
244 #
245 DocumentRoot "/Library/WebServer/Documents"
246 <Directory "/Library/WebServer/Documents">
..........
要するにDocumentRootというのは文書やコンテンツの置き場所として使われるディレクトリである.Macの場合は, DocumentRoot “/Library/WebServer/Documents” と指定されており,WWW serverとして公開する内容は,/Library/WebServer/Documents 以下に配置していくことになる.他の場所を参照するためにシンボリックリンクやエーリアスを使用しても良いと書かれている.
先ほど起動したApacheへブラウザからアクセスすると(ブラウザのurl が表示されているところにlocalhostと打てば良い)以下のような画面が表示される.
これは,/Library/WebServer/Documents/index.html.en が表示されているのである.
$ less /Library/WebServer/Documents/index.html.en
<html><body><h1>It works!</h1></body></html>
/Library/WebServer/Documents/index.html.en (END)
つまり,この /Library/WebServer/Documents ディレクトリの配下が, http://localhost のroot直下となる.pdfを含むディレクトリ,あるいはそのシンボリックリンクを/Library/WebServer/Documents ディレクトリの配下に置けば全文検索を行うcgi scriptの対象とできるわけである.
しかし,そうなると,前述の/Library/WebServer/CGI-Executables/に於いても同じであるが,全ての作業をrootとして行わなければならなくなり,何をするにもsudoしないといけないのが面倒であるし,security上でも問題であろう.そこで,UserDir ディレクティブを使って 各ユーザがホームディレクトリにSites directoryを作成し,ウェブサイトを構築できるように設定する.要するに,先ほど作成した/Users/taipapa/Sites/pdf/以下のディレクトリで全文検索ができるように設定するということである.
ユーザ毎のウェブディレクトリ
- 参照1:apacheを使ってローカルサーバーを構築する方法
- 参照2:MacOS 同梱の Apache が参照するドキュメントルートを変更する
- 参照3:MacOS X の Yosemite (10.10) で Sites ディレクトリを使って localhost をアカウント別に利用する方法
- 参照4:ユーザ毎のウェブディレクトリ
やはりApacheのチュートリアル(ユーザ毎のウェブディレクトリ)を読むのが一番分かりやすかった.以下はこのサイトからの引用
- 「複数のユーザのいるシステムでは、UserDir ディレクティブを使って 各ユーザがホームディレクトリにウェブサイトを構築できるように設定することが 可能です。URL http://example.com/~username/ を訪れた人は “username” というユーザの UserDir ディレクティブで指定された サブディレクトリからコンテンツを得ることになります。」
- 「デフォルトではこれらのディレクトリへのアクセスは許可されていません。 UserDir を使って有効にできます。 有効にするには、デフォルトの設定ファイルで付随する httpd-userdir.conf ファイルが必要」という翻訳になっている.意味はなんとなくわかるが,後半部分は「デフォルトの設定ファイルであるhttpd-userdir.conf ファイルの中の次の行をアンコメントすることによりアクセスが可能となる.また,必要に応じてhttpd-userdir.confも適切に変更する」と訳すべきと思う.
httpd-userdir.confの有効化
手順としては,まず,/etc/apache2/httpd.confの511行目の行頭の#を外し,コメントアウトを外してhttpd-userdir.confを有効にする.
$ sudo vi /etc/apache2/httpd.conf
..........
510 # User home directories
511 #Include /private/etc/apache2/extra/httpd-userdir.conf
----->
511 Include /private/etc/apache2/extra/httpd-userdir.conf
..........
httpd-userdir.confの編集(ユーザー毎の設定ファイルを読み込む様にする)
ついで,有効にした /etc/apache2/extra/httpd-userdir.confを見て,編集する.
$ sudo vi /etc/apache2/extra/httpd-userdir.conf
1 # Settings for user home directories
2 #
3 # Required module: mod_authz_core, mod_authz_host, mod_userdir
4
5 #
6 # UserDir: The name of the directory that is appended onto a user's home
7 # directory if a ~user request is received. Note that you must also set
8 # the default access control for these directories, as in the example below.
9 #
10 UserDir Sites
11
12 #
13 # Control access to UserDir directories. The following is an example
14 # for a site where these directories are restricted to read-only.
15 #
16 # Include /private/etc/apache2/users/*.conf
17 <IfModule bonjour_module>
18 RegisterUserSite customized-users
19 </IfModule>
10行目の"UserDir Sites"は デフォルトでアンコメントされており,そのままで良い.これにより,~usernameでSites directoryにアクセスできるようになる.編集する部分は,16行目の " # Include /private/etc/apache2/users/*.conf” であり,行頭の#を外してアンコメントし,有効化しておく.これによりユーザーごとの設定ファイルを読み込む様になる(MacOS X の Yosemite (10.10) で Sites ディレクトリを使って localhost をアカウント別に利用する方法).
また,3行目にあるように,ユーザーのホームディレクトリのセットアップのために, mod_authz_core, mod_authz_host, mod_userdirを全て有効 にしておく必要がある.以下のように, /etc/apache2/httpd.conf を編集する.
sudo vi /etc/apache2/httpd.conf
......
77 LoadModule authz_host_module libexec/apache2/mod_authz_host.so
78 LoadModule authz_groupfile_module libexec/apache2/mod_authz_groupfile.so
79 LoadModule authz_user_module libexec/apache2/mod_authz_user.so
80 #LoadModule authz_dbm_module libexec/apache2/mod_authz_dbm.so
81 #LoadModule authz_owner_module libexec/apache2/mod_authz_owner.so
82 #LoadModule authz_dbd_module libexec/apache2/mod_authz_dbd.so
83 LoadModule authz_core_module libexec/apache2/mod_authz_core.so
......
173 #LoadModule speling_module libexec/apache2/mod_speling.so
174 #LoadModule userdir_module libexec/apache2/mod_userdir.so
175 LoadModule alias_module libexec/apache2/mod_alias.so
...
77行目の “LoadModule authz_host_module libexec/apache2/mod_authz_host.so” と83行目の “LoadModule authz_core_module libexec/apache2/mod_authz_core.so"はデフォルトでアンコメントされていたが,174行目の “#LoadModule userdir_module libexec/apache2/mod_userdir.so” はコメントアウトされていたので,#を外して有効化した.これらの設定で, ユーザーディレクトリが有効 になる.
ユーザー毎の設定ファイルを作成
自分の使っているusernameを知らない人はいないと思うが,万一分からなければ以下のコマンドを使う.
$ whoami
taipapa
ついで,/etc/apache2/users にユーザー毎の設定ファイルを作成する.今回はtaipapaの設定ファイルということになる.
$ sudo vi /etc/apache2/users/taipapa.conf
<Directory "/Users/taipapa/Sites/">
AddHandler cgi-script cgi
AllowOverride All
Options Indexes FollowSymLinks Multiviews ExecCGI
Require all granted
</Directory>
内容を簡単に説明する.
- Directory (Directory ディレクティブ): 指定されたディレクトリとそのサブディレクトリにのみ ディレクティブを適用させるためには、 Directory と /Directory を対として、ディレクティブ群を囲む.以下はディレクティブの説明
- AddHandler (AddHandler ディレクティブ ): ファイル名の拡張子を指定されたハンドラにマップする.“AddHandler cgi-script cgi” により,/Users/taipapa/Sites/の配下にある拡張子 “.” で終わるファイルを CGI スクリプトとして扱うようになる.
- AllowOverride (AllowOverride ディレクティブ): このディレクティブが All に設定されている時には、 .htaccess という コンテキスト を持つ 全てのディレクティブが利用できる.
- Options (Options ディレクティブ): ディレクトリに対して使用可能な機能を設定する.個々の機能はリンク先を参照.今回重要なのは, ExecCGI で,これはmod_cgiによるCGI scriptの実行を許可する.
- Require (参照:Apache 2.4 設定ファイルの記述例): サーバーのディレクトリに接続してくるクライアントについて、許可・拒否する条件を指定するディレクティブ.昔はAllow ディレクティブやDeny ディレクティブを利用していた. “Require all granted” は、すべてのクライアントからの接続を許可する. “Require all denied” は、すべてのクライアントからの接続を拒否する.
これで,Apache関連の設定が終了した.次はいよいよCGI scriptの設定である.
Hyperestraier付属の全文検索用CGI scriptのset up
ようやく,ブラウザによる全文検索ができるようにするためにCGI scriptのset upをするところまでたどり着いた.hyperestraierに含まれている検索用CGI scriptは,estseek.cgiである.詳細はリンク先のマニュアルを参照していただきたい.そこにはこうある.「estseek.cgiが動作するには、設定ファイルとテンプレートファイルとトップページファイルとヘルプファイルが必要です。それぞれestseek.conf、estseek.tmpl、estseek.top、estseek.helpというのが標準的な名前です。」これらのscriptおよび関連ファイルは,brewでインストールした場合は,以下のような場所に入る.
$ mdfind -name estseek
/usr/local/Cellar/hyperestraier/1.4.13/libexec/estseek.cgi
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/locale/ja/estseek.top
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/locale/ja/estseek.tmpl
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/locale/ja/estseek.help
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/locale/ja/estseek.conf
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/increm/estseek-frame.html
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/increm/estseek-form.html
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/estseek.top
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/estseek.tmpl
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/estseek.help
/usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/estseek.conf
$ ls /usr/local/Cellar/hyperestraier/1.4.13/libexec/
estfraud.cgi* estproxy.cgi* estscout.cgi* estseek.cgi* estsupt.cgi*
$ ls /usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/
COPYING estfraud.conf estscout.conf estseek.top locale/
ChangeLog estproxy.conf estseek.conf estsupt.conf
THANKS estraier.idl estseek.help filter/
doc/ estresult.dtd estseek.tmpl increm/
そこで,これらのscriptをユーザーディレクトリのしかるべき場所にコピーする.今回は,まず,前半部で作成した/Users/taipapa/Sitesにcgi-bin というディレクトリを作成し,CGI scriptの置き場所とした.そして,その配下にestというディレクトリを作って,そこにhyperestraierによる全文検索用のscript などをコピーした.
$ cd /Users/taipapa/Sites
$ mkdir -p cgi-bin/est
$ tree -L 2
.
├── cgi-bin
│ ├── est
│ └── test.cgi
├── index.html
├── pdf
│ ├── PDFs
│ └── casket
└── test.cgi
$ cd cgi-bin/est
$ cp -a /usr/local/Cellar/hyperestraier/1.4.13/libexec/* .
$ cp -a /usr/local/Cellar/hyperestraier/1.4.13/share/hyperestraier/est* .
$ ls
estfraud.cgi* estproxy.conf estscout.cgi* estseek.conf estseek.top
estfraud.conf estraier.idl estscout.conf estseek.help estsupt.cgi*
estproxy.cgi* estresult.dtd estseek.cgi* estseek.tmpl estsupt.conf
設定ファイルであるestseek.confはdefaultでは以下のようになっている.
$ cd /Users/taipapa/Sites/cgi-bin/est
$ less -N estseek.conf
..........
1 indexname: casket
2
3 tmplfile: estseek.tmpl
4
5 topfile: estseek.top
6
7 helpfile: estseek.help
8
9 lockindex: true
10
11 pseudoindex:
12
13 replace: ^file:///home/mikio/public_html/{{!}}http://localhost/
14 replace: /index\.html?${{!}}/
15
16 showlreal: false
..........
これを以下のように編集する.
1 #indexname: casket
2 indexname: /Users/taipapa/Sites/pdf/casket
3
4 tmplfile: estseek.tmpl
5
6 topfile: estseek.top
7
8 helpfile: estseek.help
9
10 lockindex: true
11
12 pseudoindex:
13
14 #replace: ^file:///home/mikio/public_html/{{!}}http://localhost/
15 #replace: /index\.html?${{!}}/
16
17 replace: ^file:///Data/{{!}}http://localhost/~taipapa/pdf/PDFs/
18
17行目の replace: の部分はかなりの試行錯誤が必要であった.マニュアルでは,「replaceは正規表現によってURIを変換するのに使います。複数回指定できます。先頭にマッチする「^」を駆使すれば接頭辞(ディレクトリ)の変換ができますし、末尾にマッチする「$」を駆使すれば接尾辞(拡張子)の変換ができます。」とあるように,どこにpdf文書を置くかで適切に変更する必要がある.私の場合は,前述のごとく,pdfのあるディレクトリが,/Data/hogehoge, /Data/fugaguga, /Data/misc で,/Users/taipapa/Sites/pdf/PDFs にシンボリックリンクで集約したので,このような設定になった.他のファイルはdefaultのままとした.
これで,全ての準備は整った.Sites ディレクトリには前半部で説明した通り,pdf archiveへのシンボリックリンクが集約されており,かつ,全文検索用の索引であるcasketも置いてある.全てが正しく設定されていれば,ブラウザのurl windowに http://localhost/~username/cgi-bin/est/estseek.cgi (今回は~usernameは~taipapa) と打ち込むと,以下のような全文検索の画面になるはずである.
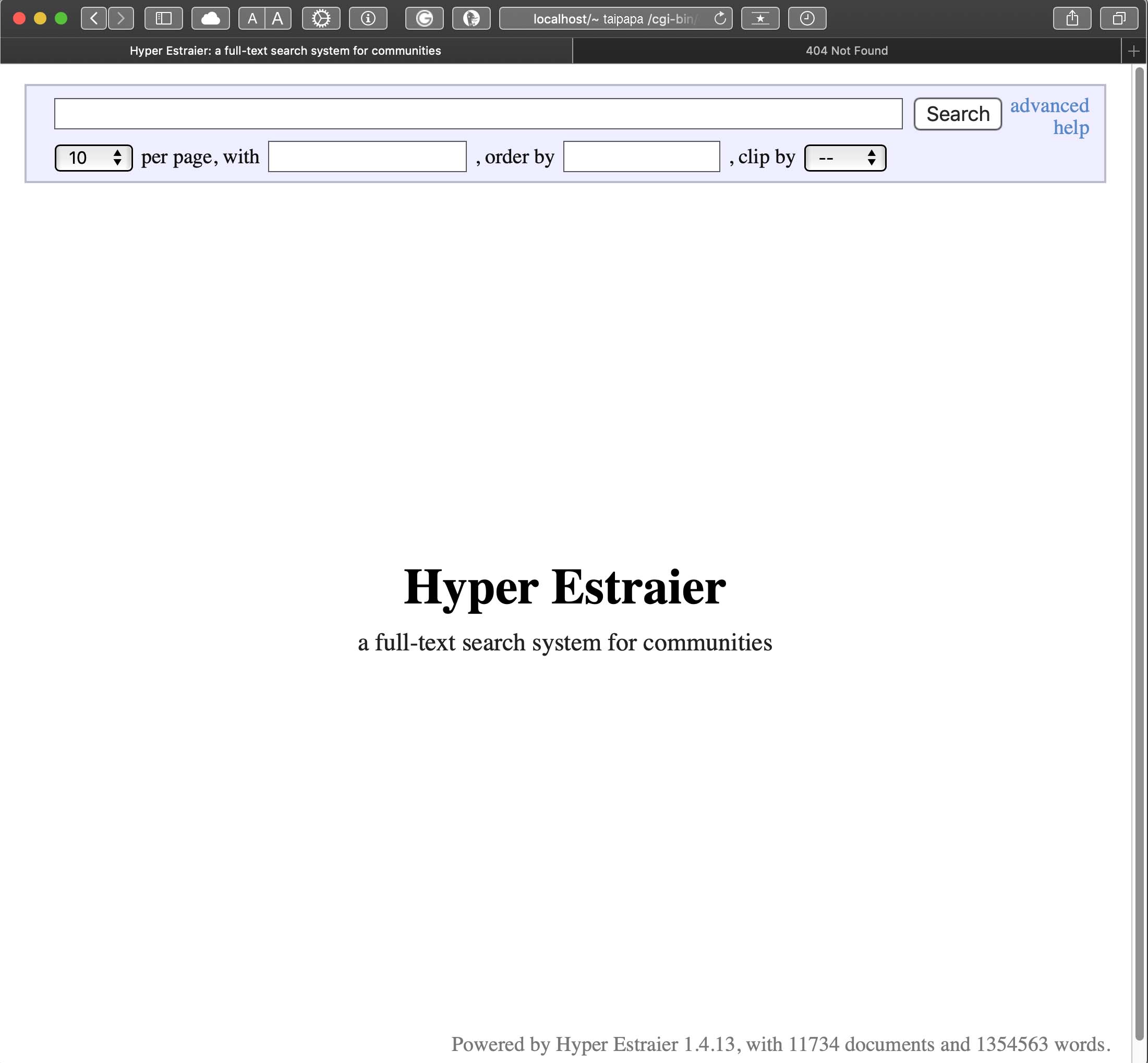
早速検索してみよう.HSP27と入れてみると,結果は以下の通り.検索に用いたキーワードが黄色でハイライトされている.
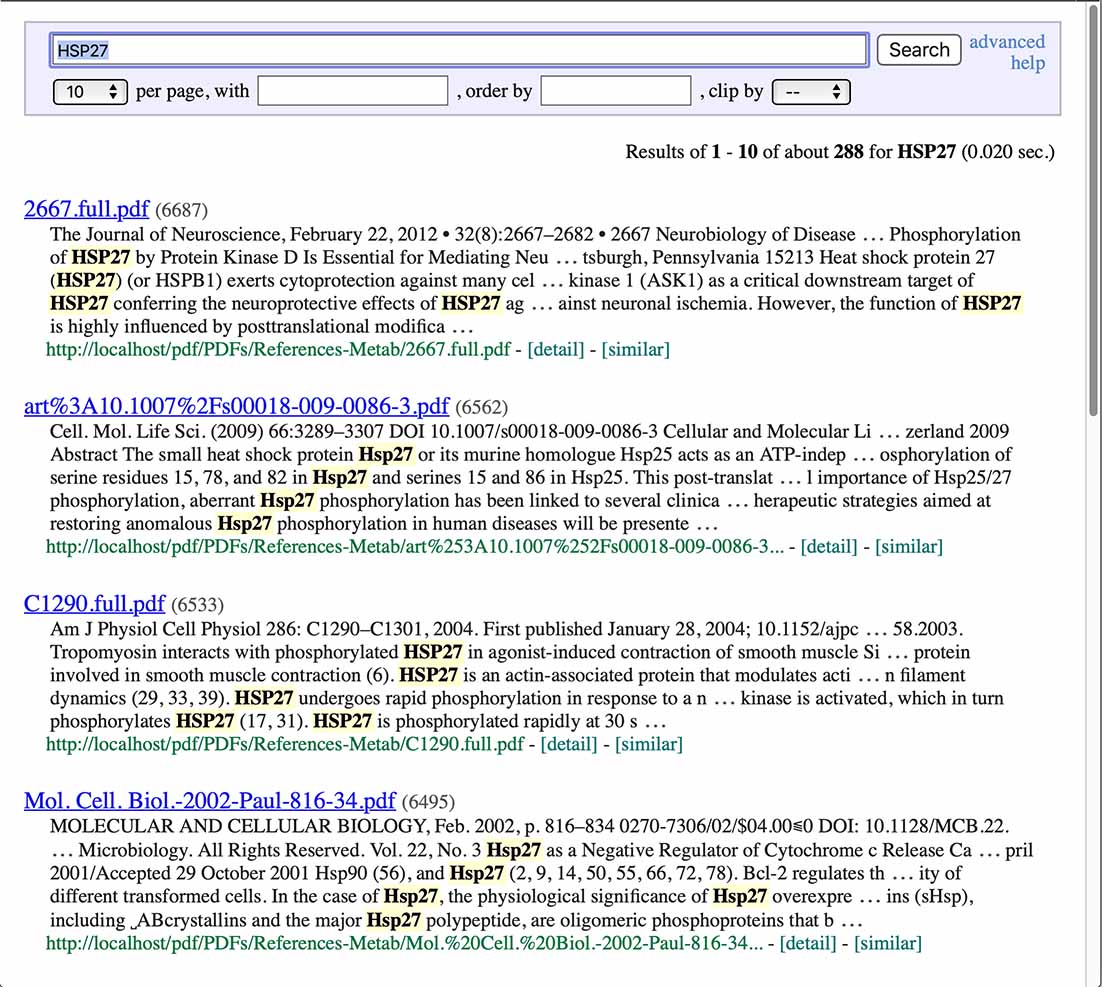
一番最初の2667.full.pdfを右クリックすると,下のように別タブでpdfが開く.

また,各結果の[detail]の部分を右クリックすると以下のような画面が別タブで開く.
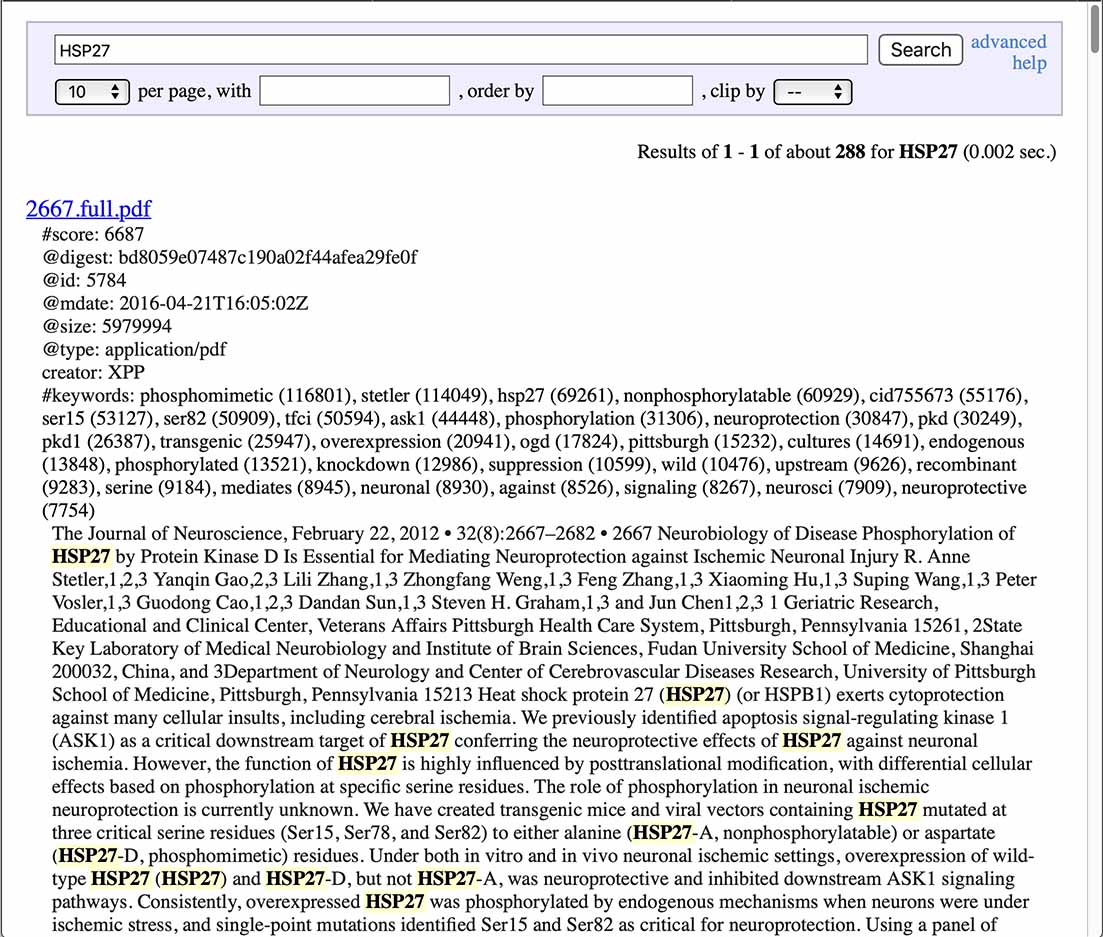
これは,pdfの内容をテキストで出力したものである.一見,見にくくて何の役にたつと思うかもしれないが,検索キーワードが黄色にハイライトされており,この単語の使い方が一目でわかるようになっている.論文を書くときに参考になる.
この全文検索を使い始めてもう5-6年になるが,一旦セットアップしてしまえば,時々indexを更新する以外は手間いらずで,重宝している.更新の自動化については,前述の通り.
今回は,このブログを始めて以来の長文になってしまった.後日の自分のためにできるだけ細かいところまで書き留めておいた.半分以上はApacheの設定に関する記述になっている(笑).