
次世代grepで最速と言われるripgrepをバックエンドとするEmacs用検索ツールであるdeadgrepをインストールしてみた.
Ref
- deadgrep: use ripgrep from Emacs ご本家
- 複雑になった時使うツール とても勉強になるサイト,こちらを読めば本サイトは読まなくても良いような...
Install
まず,バックエンドのripgrepをインストールする.brewを使えば簡単である.
$ brew install ripgrep
ついで,以下のようにinit.orgに書き込んでMRLPAからdeadgrep.elをインストールする.f5にキーバインドしておく.
#+begin_src emacs-lisp
(use-package deadgrep
:ensure t
:config
(global-set-key (kbd "<f5>") #'deadgrep)
)
#+end_src
How to use
使用方法の詳細はご本家に書いてあるが,f5を叩いて,検索キーワードを入れるだけである.下の画像は,このブログのあるdirectoryで,「検索」をキーワードとしてdeadgrepを走らせたところである.defaultでdirectory内を再帰的に検索する.キーワードは青くハイライトされており,左端の数字はその文書での行番号である. o を叩くと下のバッファに該当箇所にカーソルがある状態でその文書が開く. C-c C-k で検索を止めることができる.また,swiperとの併用も可能である.
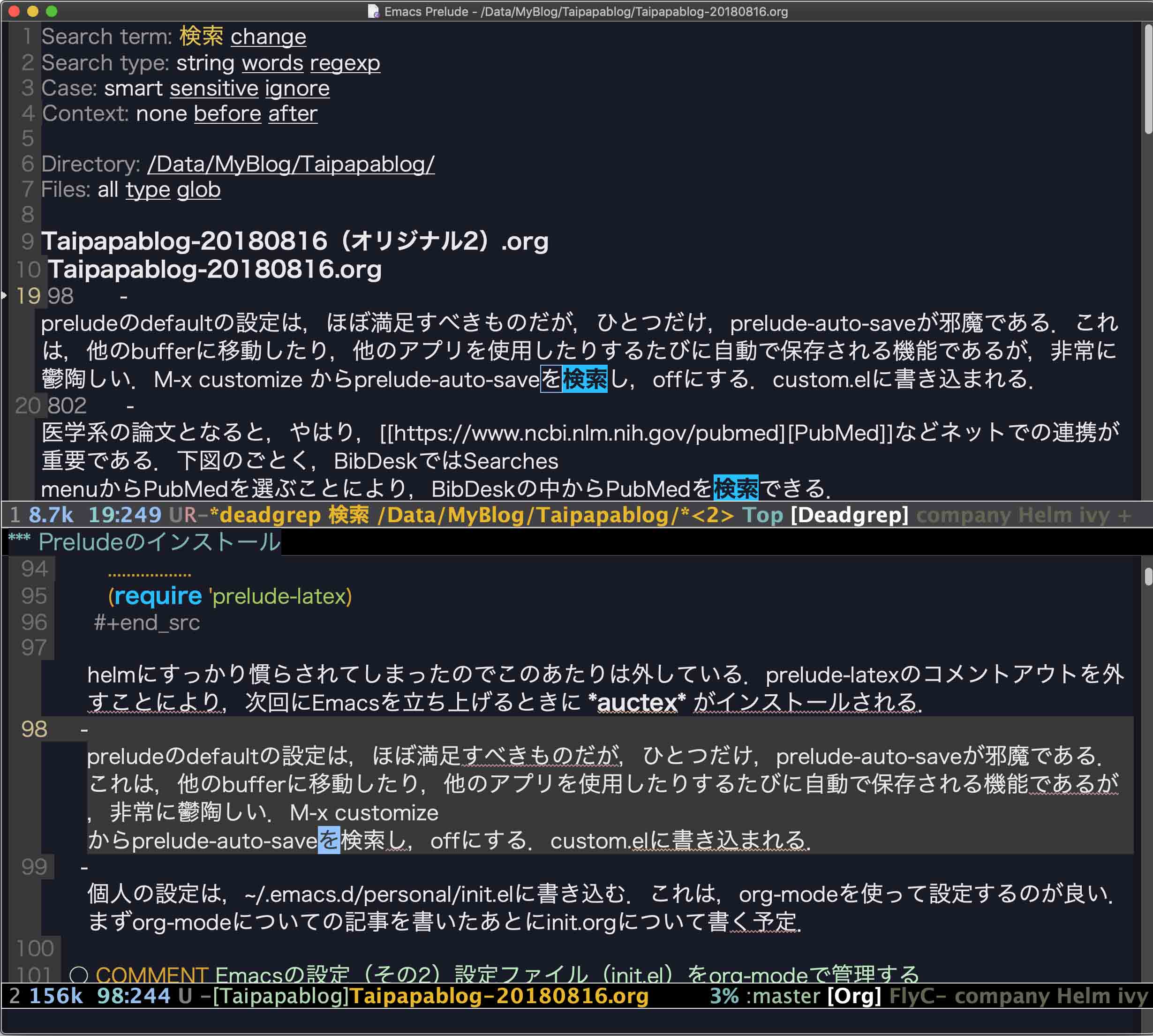
一番上のSearch termの行のchangeにカーソルを持っていってReturnすると,Minibufferで検索語を変更できる.その下にあるSearch type, Case, Context, Directory, Filesも同様に条件を変更できる.とくに,Directoryは適切なものを選ばないと巨大なデータを検索することになってしまうので注意が必要である.
個人的には,swiperでほぼ事足りているのだが,大きなプロジェクト内の複数のファイルを一気に検索する必要がある人には非常に有益なツールだと思う.
2019年6月2日追記
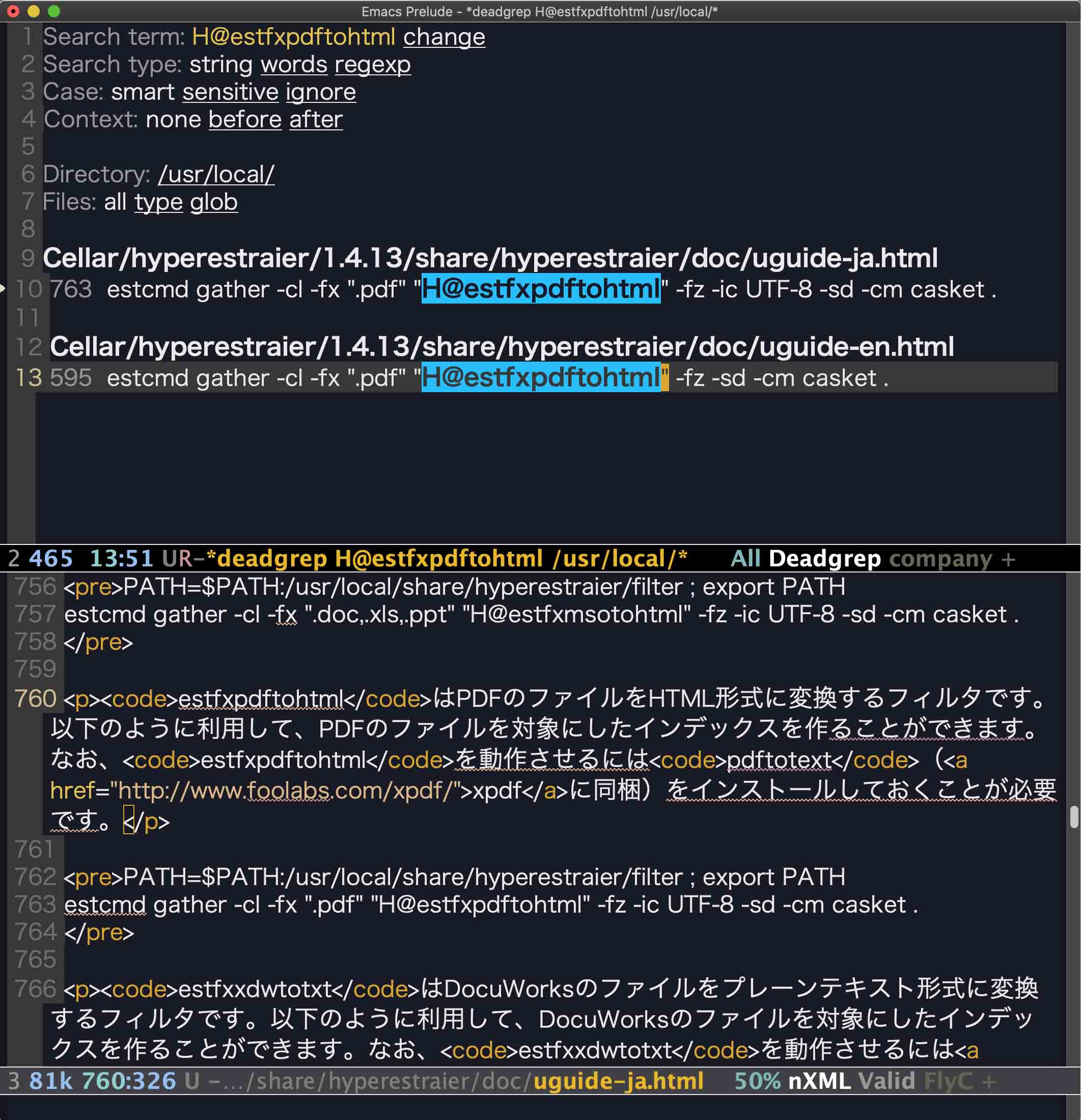
上記のように自分にはあまり役に立たないようなことを書いたが,早速,deadgrepが役に立ったので追記しておく.hyperestraierで全文検索をしようとして,H@estfxpdftohtml というコマンドを使おうとしたのだが,うまくいかず,その原因を探るために,/usr/local/で,H@estfxpdftohtmlをSearch termとして,deadgrepを下の画像のように走らせてみたところ,下側のバッファにあるように,一発で原因が判明してしまった.要するに,xpdfが必要ということであった.なるほど,こういう風に使うのかと納得した.
なお,全文検索については,いずれ別の機会にまとめてみたい.